Invalid Email Address!!! How it works. (Part 1)

If you developed applications that enabled users to sign in/up before , you certainly came across something related to regular expressions or more abstractly this bunch of random characters you copied somewhere online that magically validate the user input for you. For example if you are javascript user , in your code you will find something similar to this snippet :
function MailValidate(mail)
{
if (/^[a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+@[a-zA-Z0-9-]+(?:\.[a-zA-Z0-9-]+)*$/.test(myForm.email.value))
{
return (true)
}
alert("You have entered an invalid email address!")
return (false)
}
What is the idea behind those characters? How they work? Who invented them? What the heck is a regular expression and Why should you care. In this article I will discuss regular expressions in the R programming language but the ideas can be applied to any programming language. Regular expression can take ages to discuss how they work and the development that took and is taking place to improve their performance but in this article I will give an overview about their mechanics.
📜 A Brief History of Time

Stephen Cole Kleene or simply Kleene was the American mathematician that introduced the concept of regular expressions to programmers. He alongside other scientists provided the foundations of theoretical computer science. And in 1951 he invented regular expressions as a way to describe neural networks at the time.
During World War II, Kleene was a lieutenant commander in the United States Navy. He was an instructor of navigation at the U.S. Naval Reserve's Midshipmen's School in New York, and then a project director at the Naval Research Laboratory in Washington, D.C. In 1990 he was awarded the National Medal of Science.
🔍A Deeper Look on Regex
Regular expressions are a notation for describing sets of character strings. When a particular string is in the set described by a regular expression, we often say that the regular expression matches the string.
You can think about regex to be as simple as a letter in the English language : 'x' for example matches the string 'extreme' because x is the second letter in the string. Before you start to feel happy about their simplicity , I have to warn you that regular expressions can be extremely complex that a computer can take a 1015 years to compute them-You read that right this is not a typo.
The mighty META *+?()| metacharacters , +, and ? are repetition operators: x* matches a sequence of zero or more (possibly different) strings, each of which match x; x+ matches one or more; x? matches zero or one. Two regular expressions can be alternated or concatenated to form a new regular expression: if x matches s and y matches t, then x|y matches s or t, and xy matches st. Just as in arithmetic expressions. Some examples: xy|zd is equivalent to (xy)|(zd); xy is equivalent to x(y*). This is the same syntax you would find in the UNIX egrep method however new "syntax" was introduced to enhance the outputs (and not necessarily the performance of the expressions). For example One common regular expression extension that does provide additional power is called backreferences. A backreference like \1 or \2 matches the string matched by a previous parenthesized expression, and only that string: (tar|bar)\1 matches tartar and barbar but not bartar nor tarbar. This power costs developers an exponential time complexity and with web services this is not a great idea at all. Will discuss why later in the article. I just want you to understand that combining these meta characters is the way we validate if the user entered a valid email format or not.
🎬 Behind the Scenes
Strings could also be represented as state machine ( also known as Finite Automata ), the following machine will recognize the strings that is matched by this pattern "HEL(L)*o" , recall that in a state machine the end state is indicated by a double layer circle .
DFA :
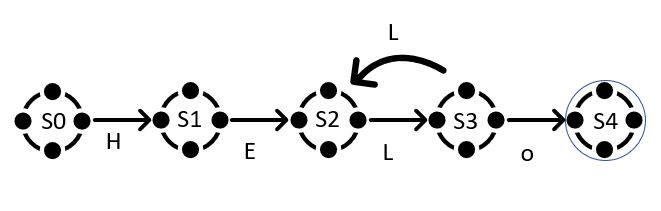
This is the sequence needed to make a match in the above diagram:
HELo : S0,S1,S2,S4
HELLo : S0,S1,S2,S3,S2,S3,S4
HELLLo : S0,S1,S2,S3,S2,S3,S2,S3,S4 and so on.
The machine we have been considering is called a deterministic finite automaton (DFA), because in any state, each possible input letter leads to at most one new state. We can also create machines that must choose between multiple possible next states. For example, this machine is equivalent to the previous one but is not deterministic as letter L can get you to 2 different states:
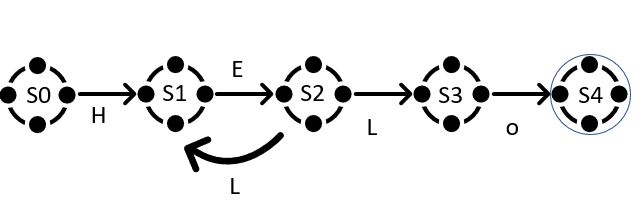
Such machines are called non-deterministic finite automata (NFAs or NDFAs). An NFA matches an input string if there is some way it can read the string and follow arrows to a matching state. In the next article I will talk in depth about the search algorithms that are used in the regular expression engines but for now I will give a motivation why you should care about knowing this information by benchmarking the performance of different regular expression libraries.
⚖️ Benchmarks In this example I will benchmark 4 regular expression libraries ( PCRE, TRE, Stringi ,Google's re2)that are used in R but all of them has their own interfaces in other languages.
Case 1: a kind regex I will be using a kaggle data set to extract information related to a locations crimes in USA.
homicides <- readLines("homicides.txt")
max.N <- 25
times.list <- list()
for(N in 1:max.N){
cat(sprintf("subject/pattern size %4d / %4d\n", N, max.N))
x<-paste(homicides[1:N], collapse=" ")
N.times <- microbenchmark::microbenchmark(
ICU= stringi::stri_match(x, regex="<dd>[F|f]ound(.*?)</dd>"),
PCRE= regexpr("<dd>[F|f]ound(.*?)</dd>", x, perl=TRUE),
TRE=regexpr("<dd>[F|f]ound(.*?)</dd>", x, perl=FALSE),
RE2=re2r::re2_match(x,"<dd>[F|f]ound(?P<Date>.*?)</dd>" ),
times=10)
times.list[[N]] <- data.frame(N, N.times)
}
times <- do.call(rbind, times.list)
save(times, file="times.RData")
The following graph shown the performance of the 4 libraries:
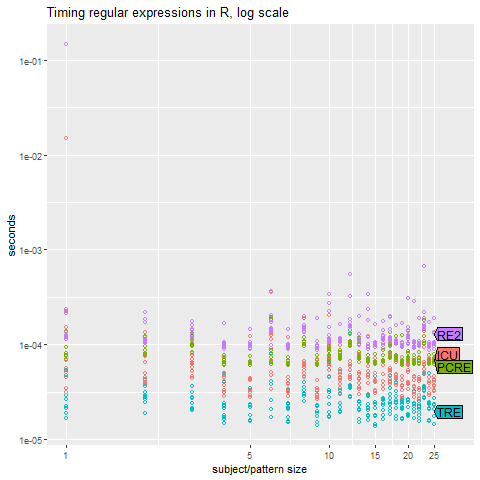 as expected for a basic regex the performance of all the libraries is nearly the same, but what if we applied an evil regex. PCRE and Stringi are both based on a recursive backtracking algorithm that with evil regular expressions can have an exponential time complexity.
as expected for a basic regex the performance of all the libraries is nearly the same, but what if we applied an evil regex. PCRE and Stringi are both based on a recursive backtracking algorithm that with evil regular expressions can have an exponential time complexity.
Case 2 : evil Regex
Consider the regular expression a?nan. It matches the string an when the a? are chosen not to match any letters, leaving the entire string to be matched by the an. Backtracking regular expression implementations implement the zero-or-one ? by first trying one and then zero. There are n such choices to make, a total of 2n possibilities. Only the very last possibility—choosing zero for all the ?—will lead to a match. The backtracking approach thus requires O(2n) time, so it will not scale much beyond n=25. The same idea goes with (a+)+$. This is an example of an evil regex:
evilRegex<-function(){
max.N <- 25
times.list <- list()
for(N in 1:max.N){
cat(sprintf("subject/pattern size %4d / %4d\n", N, max.N))
subject <- paste(rep(c("a","X"), c(N,1)), collapse="")
pattern <- "^(a+)+$"
N.times <- microbenchmark::microbenchmark(
ICU=stringi::stri_match(subject, regex=pattern),
PCRE=regexpr(pattern, subject, perl=TRUE),
TRE=regexpr(pattern, subject, perl=FALSE),
RE2=re2r::re2_match(subject, pattern),
times=10)
times.list[[N]] <- data.frame(N, N.times)
}
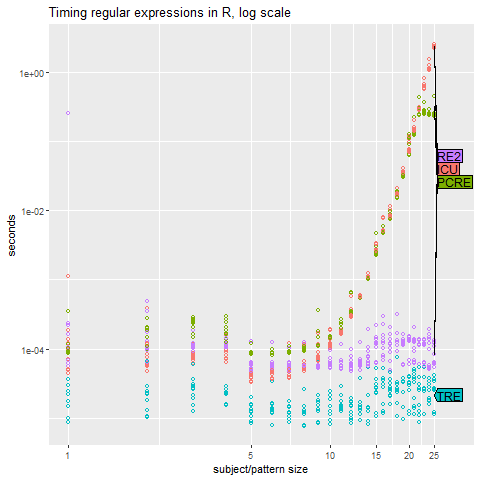
as expected now the difference is very clear , the polynomial time complexity of RE2 and TRE makes them the stars of the scene. But what is unique about them. Part 2 will discuss the smart algorithms behind this graph. Wait for it.

